Contexte
Dans mon dernier livre aux Editions Packt Publishing (https://www.amazon.com/dp/1835085660), j'explique comment concevoir un Système d'Information en l'alignant au maximum sur le métier, de façon à le rendre évolutif. Je pars de notions de stratégies digitales et, comme j'aime bien démontrer de façon pratique les avantages de cette méthode, une grande partie du livre est consacrée à monter de toutes pièces un mini-SI exemple, qui utilise des services externes (Keycloak, Alfresco, RabbitMQ, MongoDB, etc.) ainsi que d'autres développés en .NET.
Le résultat est une application, ou plutôt un ensemble de services constituant un Si réduit, que vous pouvez trouver sur https://github.com/PacktPublishing/Enterprise-Architecture-with-.NET. De façon à simplifier au maximum le lien entre le code et le livre, le code des services est fortement simplifié (alors que l'architecture, elle, est la plus alignée possible avec les concepts de découplage et de modularisation qui sont mis en avant dans le livre). Cette simplification a bien sûr un coût en termes de dette technique. Par exemple, les URL sont codées en dur. Ce n'est pas le plus grave car la gestion par service de Docker Compose lève une bonne partie du problème. Mais aucun des services introduits ne l'est en utilisant l'injection, ce qui est plus gênant. De même, certaines classes pourtant communes n'ont pas été partagées, alors qu'elles relèvent de contrats fonctionnels pour les API et auraient donc pu l'être.
Objectifs
Comment objectiver la situation et proposer des solutions ? Il existe une branche v1.0 qui permet de garder l'application telle quelle en lien avec le livre, mais des évolutions seront portées sur la branche main pour lever les manques les plus criants en termes de code. Des TODO ont été placés dans le code et certaines limitations volontaires ont été expliquées ci-dessus, mais d'autres existent très certainement.
Comment les trouver ? NDepend, bien sûr ! Le couteau-suisse de l'architecte logiciel sera le parfait outil pour retrouver les caractéristiques architecturales de l'ensemble du système, mais aussi avoir un oeil critique sur celles-ci ainsi que sur le code d'implémentation des différents services compose ce dernier.
Lancement de l'analyse NDepend
Comme je n'ai pas utilisé une solution Visual Studio mais que le système est composé de plusieurs projets avec des services les plus découplés possibles, on pourrait se demander comment lancer l'analyse de l'ensemble, mais NDepend permet de se baser sur les librairies d'un dossier :
Et ce qui est très pratique est qu'on peut parcourir récursivement le dossier DemoEditor qui nous intéresse :

Après un peu de temps pour le scan (il faut bien sûr avoir compilé les applications dans ce cas au préalable, et je vous conseille de ne pas incorporer l'application mobile dans l'analyse, car elle est un peu à part dans le SI exemple), vous pourrez sélectionner les librairies et supprimer les dépendances qui ne vous intéressent pas. Ensuite, un coup d'analyse - je suis toujours étonné de la vitesse de l'opération vus le nombre et la complexité des métriques qui en ressortent - et vous arrivez sur le tableau de bord de NDepend, qui va nous permettre de vérifier quelques hypothèses et étudier le SI DemoEditor.
Gestion des dépendances
Après un peu de remaniement dans le graphe des dépendances, voici notre point de départ sur la gestion du sujet :
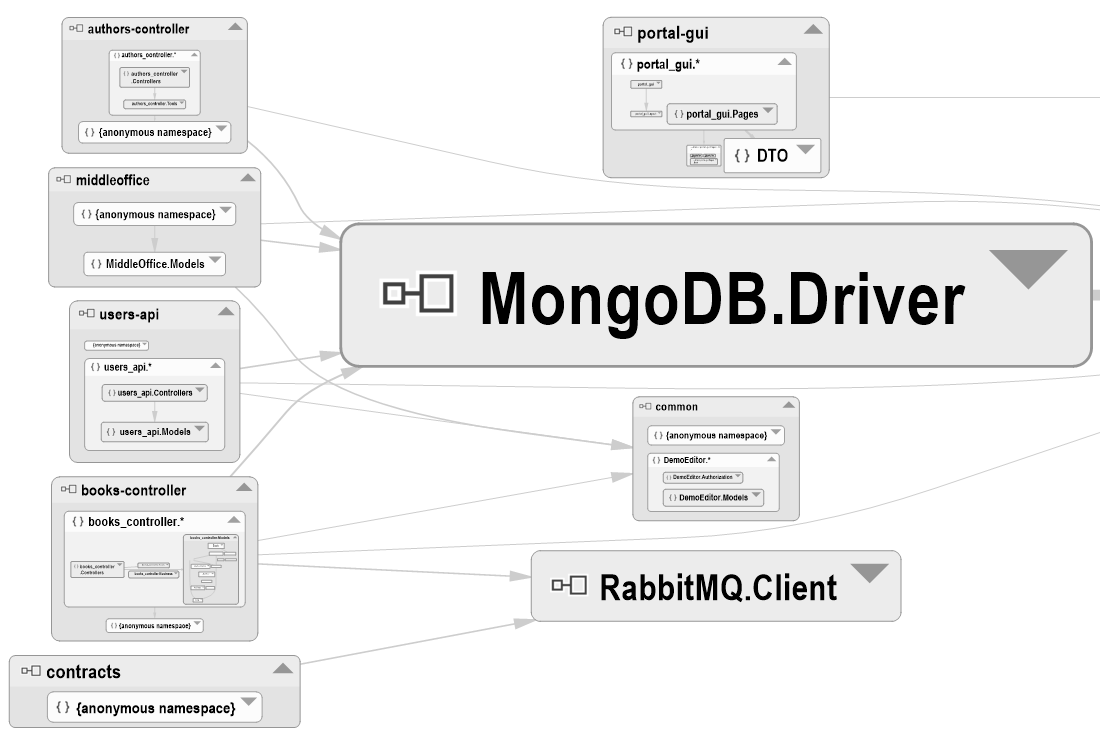
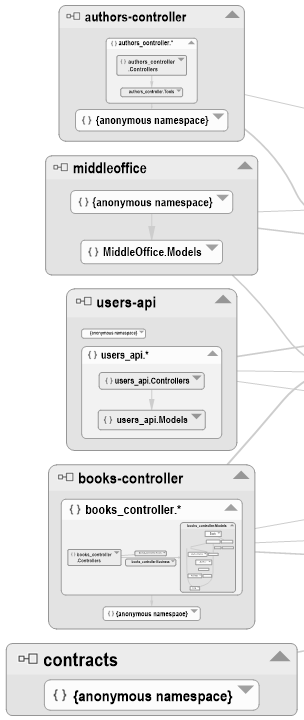
Premier point essentiel à vérifier : les implémentations des contrôleurs d'API n'ont pas de dépendances directes entre elles. Il s'agit d'un des points principaux de l'architecture qu'il convenait de vérifier, car tout le principe du couplage lâche repose sur le fait que les services se composent comme des silos indépendants, l'un pouvant tout-à-fait aller jusqu'à être codé dans un autre langage plus adapté à son contexte si nécessaire. Dans le cas du SI exemple, pour des raisons de simplicité, tous les services codés l'ont été en C#, donc il devenait plus simple de faire une erreur et de recréer du couplage. On voit que ce n'est pas le cas, car il n'y a aucun lien entre les cinq services de back office:
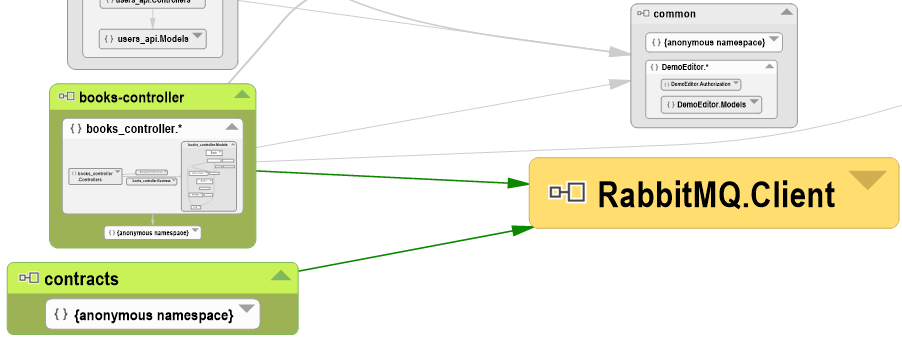
On retrouve bien sûr des dépendances communes, qui donnent une idée des couplages faibles qui existent dans l'application. Par exemple, le service contracts et le service books échangent des informations par les queues de messages RabbitMQ. NDepend ne peut bien sûr pas analyser les queues de messages elles-mêmes, mais il montre clairement que les deux services utilisent la librairie RabbitMQ.Client :
De la même manière, les services utilisent tous la librairie MongoDB.Driver, ce qui pourrait créer un couplage :
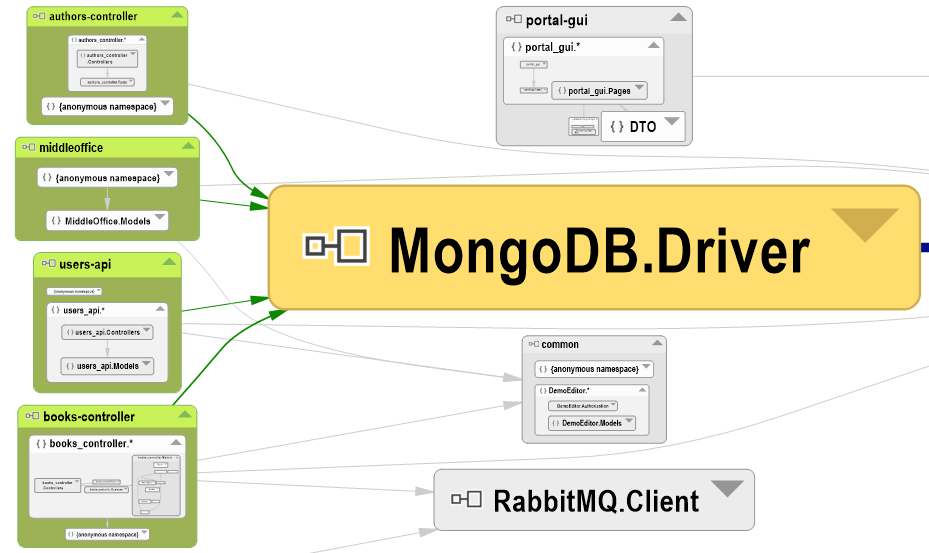
Dans le cas de l'exemple, j'ai bien sûr fait attention à ce que chaque service ait sa propre base de données pour respecter le silo, mais je n'ai pas poussé jusqu'à dupliquer les instances de MongoDB. Cela serait bien sûr facile, surtout avec Docker, mais le découplage est suffisant en gardant soin de séparer les bases. Dans un cas un peu plus complexe ou si l'ont souhaité vérifier de manière plus sûre, on aurait pu créer des clients typés pour MongoDB et l'analyse des dépendances de NDepend aurait montré que chaque service utilisait son propre client et ne pointait par sur ceux des autres.
Au passage, le graphe montre qu'il y a une dépendance directe sur le MongoDB.Driver, ce qui couple les implémentations à une base de données. Ce choix de simplicité est expliqué plus en détails dans le livre avec les pours et les contres, mais je le résumerai ici par le fait qu'un changement de base est finalement assez rare, que le protocole Mongo est désormais assez standard pour les bases de données NoSQL orientées documents... et que chaque service étant de taille limitée, le portage sur un autre mécanisme de persistance serait assez rapide.
Une autre analyse dépendances en plaçant la souris sur le projet common rappelle que la mise en commun des modèles métier a commencé (on n'est donc pas aussi loin d'une clean architecture que le paragraphe précédent pouvait le laisser craindre), mais ne concerne pas tout le monde :
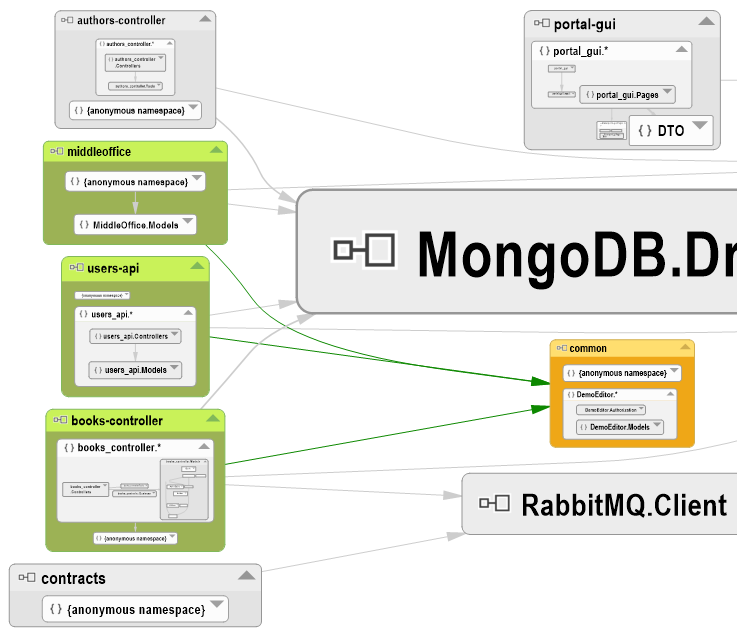
Il y a en effet un partage de common par trois des services back office, mais celui sur les auteurs et celui sur les contrats ne pointent pour l'instant pas dessus. C'est donc un autre TODO qu'il faudra réaliser pour la suite de l'application exemple. Une bonne nouvelle, par contre, est que les classes qui ont été mises dans common sont de pures classes métier telles que définies en clean architecture / architecture hexagonale, dans le sens où elles ne contiennent aucune dépendance à des attributs Mongo par exemple.
Pour l'instant, il ne s'agit toutefois que de classes utilitaires, donc il était relativement simple de les éloigner de toute dépendances :
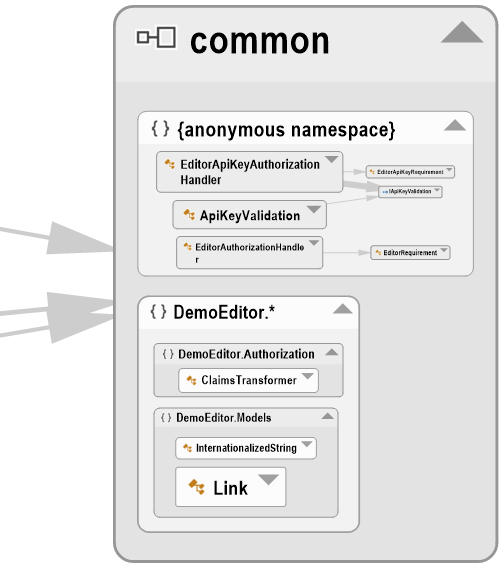
Pour des classes réellement métier, il faudra peut-être considérer une dépendance à des attributs de sérialisation JSON, par exemple, comme suffisamment générique pour être acceptable. Personnellement, comme pour l'injection où je me méfie comme de la peste de l'habitude de tout injecter, y compris des classes qu'on ne remplacera jamais, je me méfie de la trop grande rigidité dans l'application de l'architecture hexagonale consistant à n'accepter aucune dépendance directe sur les classes métiers.
Matrice de dépendances
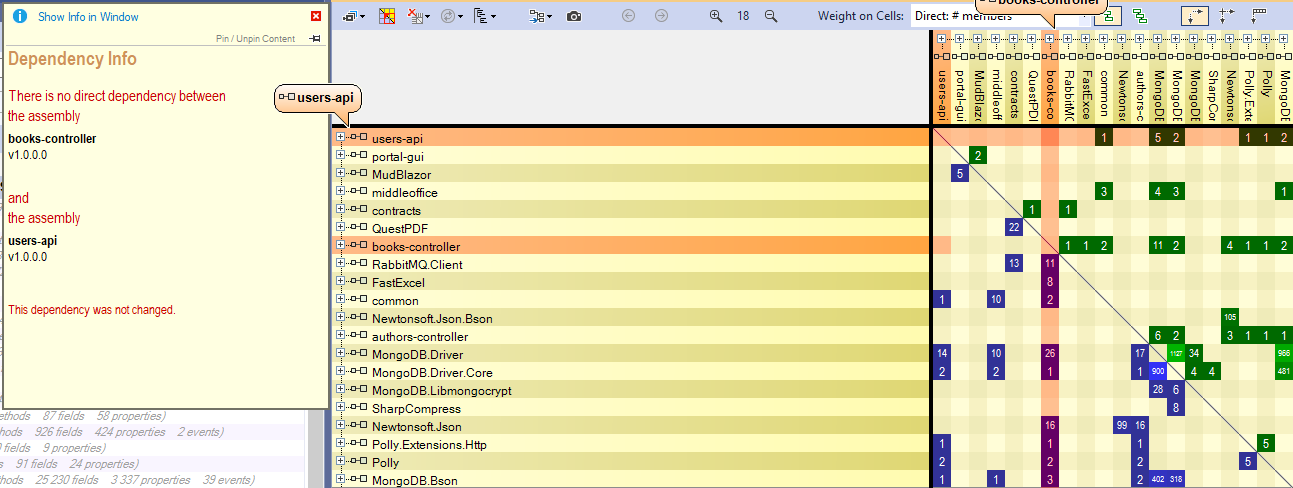
La matrice des dépendances permet de vérifier aussi en un seul et même endroit que les différents services n'ont pas de relation entre eux :
Dashboard
Jusqu'à maintenant, pas trop de surprise mais NDepend nous a permis de corroborer les choix architecturaux qui ont été réalisés et, surtout, de vérifier qu'ils avaient effectivement été suivis dans tous les cas prévus. Pour analyser le niveau de dette dans le code (comme expliqué, le code n'est pas fait pour être propre et sophistiqué, mais pour permettre de la façon la plus simple possible la compréhension des concepts venant du livre), c'est le dashboard de NDepend qui sera le plus adapté.
Par défaut, quand on lance la première fois l'analyse, on voit les résultats des assemblages .NET inclus. Et dans la première partie de l'analyse, j'avais volontairement ajouté les dépendances principales pour pouvoir regarder les couplages lâches par les technologies associées. Dans cette seconde étape, je relance l'analyse uniquement sur les 6 librairies qui correspondent aux parties "custom" du système d'information étudié, à savoir :

De cette manière, non seulement je récupère les résultats sur mon code (je ne cherche pas en premier lieu à connaître le niveau de dette des dépendances), mais en plus je peux tout de même voir la différence par rapport à l'ensemble, ce qui me permet de me situer. Toutefois, il faudra bien sûr garder en tête que le nombre d'instructions est divisé par plus de 30 :
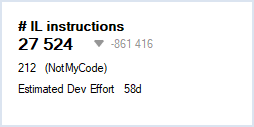
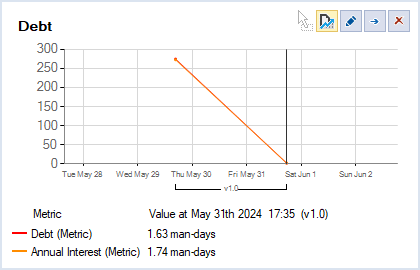
Du coup, la baisse de dette technique évaluée est très rassurante, car elle est d'un facteur bien supérieur à 30 :
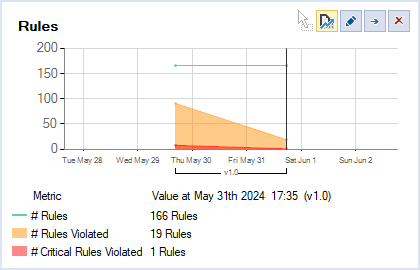
A l'inverse, les règles de qualité de code ne descendent pas d'autant, et de loin :
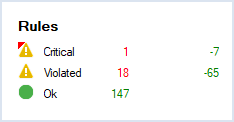
Ce qui veut dire que c'est sur ces règles qu'il va falloir particulièrement se pencher. L'état un peu au-dessus dans le dashboard montre de manière numérique la baisse relativement faible et permet de sélectionner les catégories à étudier :
Violations des règles de codage
La règle la plus critique qui a été ignorée est celle sur le nommage des classes :

Dans un premier temps, je ne voyais pas trop d'où ça venait, mais en double-cliquant sur le libellé de la règle, on retrouve tous les cas concernés :
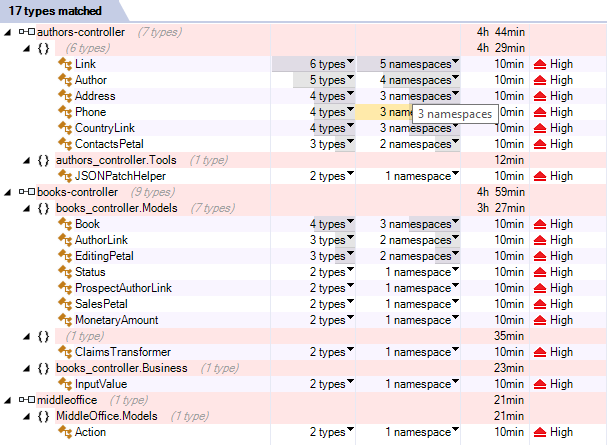
Et effectivement, comme expliqué dans le README.md de DemoEditor, je n'ai pour l'instant pas regroupé toutes les classes de modèle dans la librairie common, qui ne contient pour l'instant que les classes communes nécessaires à la transformation des claims d'authentification ou à la récupération des rôles de niveau realm. Ce sera donc un TODO prioritaire sur le projet.
Comme c'est la seule critique, et qu'elle est un peu longue à traiter, je mets le TODO dans le bon fichier et je passe aux règles non critiques :
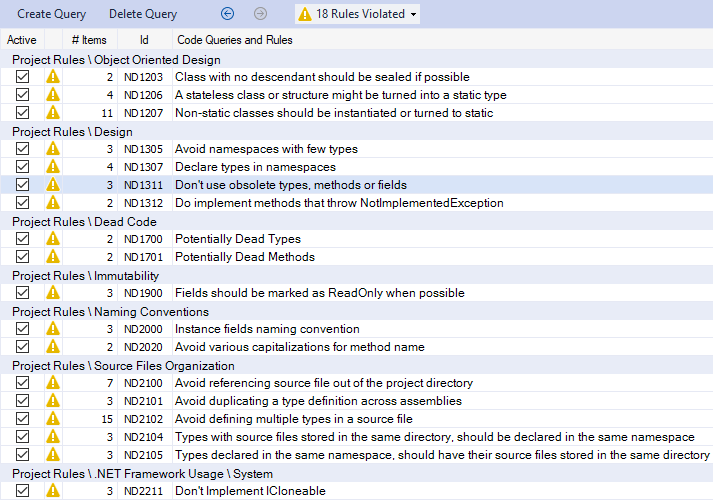
Globalement, ça n'a effectivement pas l'air trop critique, donc on va les prendre une par une, et parfois les laisser de côté. Par exemple, Avoid namespaces with few types n'est pas problématique, car le code est censé grossir assez rapidement. De même, Declare types in namespaces vient du fait que je n'ai pas utilisé les espaces de nommage par défaut dans mes projets, ce qui n'est pas un réel problème pour un tel exercice qui sert juste d'exemple.
De même, les trois violations de règles de type Object Oriented Design ne me soucient pas trop :

En les déselectionnant, cela permet d'avoir une vue un peu plus propre et de se concentrer sur ce qu'on va traiter :
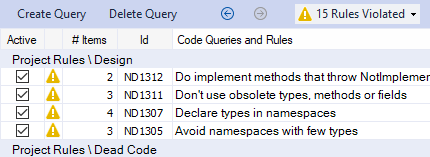
Pour ce qui est de la règle Do implement methods that throw NotImplementedException, j'avoue que je ne voyais pas en quoi c'était un problème, car il s'agissait d'une action volontaire de ma part de marquer les deux endroits du code comme explicitement pas encore implémentés. Heureusement, NDepend fournit la description plus complète :
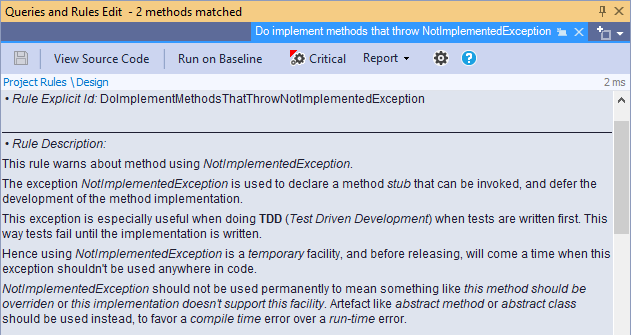
En regardant les deux méthodes, un point attire toutefois l'attention, à savoir que la sévérité n'est pas la même, ce qui peut paraître étonnant vu qu'il s'agit de la même règle :
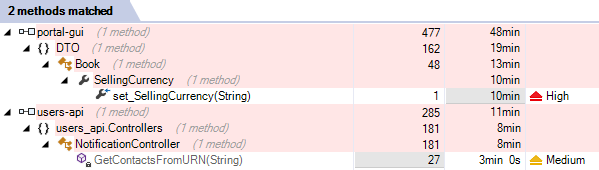
Là encore, NDepend indique le pourquoi du comment :

Je considère toutefois que ce problème n'en est pas vraiment un dans une application qui n'est pas destinée à de la production mais juste à titre d'exercice pédagogique. Intéressant par contre de prendre en compte que ReplaceOneAsync était obsolète, vu que je ne l'avais même pas remarqué en réalisant le code :
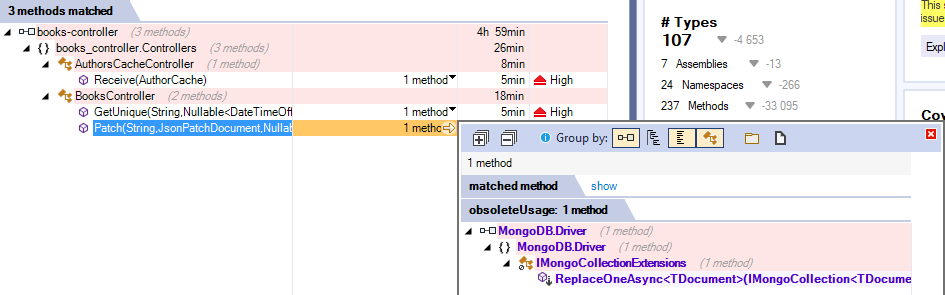
Je me demandais par quelle fonction j'allais remplacer, mais la doc indique que ce n'est pas la méthode dans sa globalité qui est obsolète, mais juste sa surcharge avec UpdateOptions qui doit être remplacée par celle utilisant ReplaceOptions :
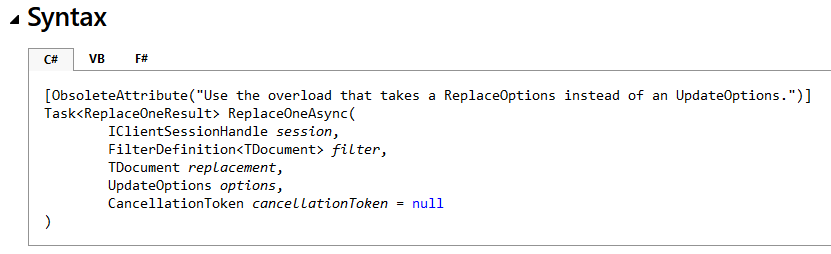
La mise à jour est donc quasi-immédiate, le nouveau code étant comme suit :
await Database.GetCollection<AuthorCache>("authors-bestsofar-cache").ReplaceOneAsync<AuthorCache>(item => item.EntityId == author.EntityId, author, new ReplaceOptions { IsUpsert = true });
Gestion des classes et méthodes mortes
Deux méthodes sont détectées comme potentiellement mortes :
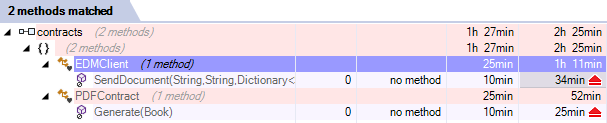
NDepend indique dans la documentation contextuelle que l'analyse statique peut ne pas suffire, et il y a effectivement une erreur, car les fonctions sont bien appelées, et depuis le même projet. Il n'est pas impossible toutefois que ce soit l'appel en provenance de Program.cs qui soit manqué, de par la nature particulière de cette classe. Pour ce qui est des types morts, ce sont les mêmes classes qui sont ignorées, donc le problème est le même dans les deux cas. Peut-être celui vient-il du fait qu'elles ont été déclarées internal ? A creuser...
Autres violations de règles de codage
Les règles de type Source Files Organization sont laissées de côté, pour les mêmes raisons que celles - liées - sur la gestion des espaces de nommage. Et dans le cas de Avoid defining multiple types in a source file, je vais même ignorer pleinement cette règle car je trouve au contraire logique de regrouper dans un même fichier les classes uniquement utilisées dans une autre :
public class Contacts
{
public List<Address> Addresses { get; set; } = new List<Address>();
public List<Phone> Phones { get; set; } = new List<Phone>();
public List<Email> Emails { get; set; } = new List<Email>();
}
public class Address
{
public string AddressType { get; set; }
public string? StreetNumber { get; set; }
public string? StreetName { get; set; }
public string? CityName { get; set; }
public string? ZipCode { get; set; }
}
public class Phone
{
public string IANAType { get; set; }
public string Number { get; set; }
}
public class Email
{
public string IANAType { get; set; }
public string EmailAddress { get; set; }
}
D'ailleurs, il serait logique de l'étendre aux classes correspondant à une entité métier supérieure en Domain Driven Design, en incluant dans le même fichier les définitions des classes de type "pétales" qui viennent autour des attributs principaux de la donnée référentielle. Je le rajoute en TODO du projet DemoEditor.
Enfin, au temps pour moi qui croyais bien faire en implémentant ICloneable au lieu de simplement sérialiser / désérialiser en JSON pour créer une copie comme un cochon : je découvre que c'est une mauvaise habitude de le faire :

Je supprime donc la déclaration d'interface du code, tout en gardant la méthode dont j'ai besoin :
public class Book
{
// ...
public object Clone()
{
string serialized = JsonSerializer.Serialize(this);
return JsonSerializer.Deserialize<Book>(serialized);
}
}
Conclusion
Malgré le manque total de tests unitaires pour l'instant, ce qui empêche de tirer partie des métriques de NDepend sur le sujet, ou d'approfondir le niveau de dette grâce au taux de couverture, le résumé n'est pas trop mal pour ce code pourtant pas très propre :

L'avantage est que NDepend m'a permis ainsi de rapidement trouver les points sur lesquels la simplicité voulue contrevenait trop aux bonnes pratiques (et les corriger) et ceux sur lesquels je pouvais me permettre de laisser tel quel, sans que cela soit trop gênant dans mes applications exemples.
Le plus étonnant est qu'en réalisant toute cette analyse et les corrections proposées, je n'ai touché que 10% de la puissance de NDepend, qui propose de nombreuses fonctionnalités suppléméntaires. Les dernières versions permettent d'importer des analyseurs Roslyn et, ça, il faudra que je teste un de ces jours, mais ce sera pour un prochain billet de blog... En attendant, un grand merci à Patrick de m'avoir fourni une license pour tester cette nouvelle version !